Note To The Reader This is not the only solution to this problem, nor I’m advocating to use services out of their scope/use-case. The same could be achieved with event queues and also with an additional lambda function that keeps track of processing that is frequently invoked via Cloudwatch events or simply use ECS or a good old EC2 VM — This specific approach was chosen only because it was a requirement for a project that I’ve worked on. As always, do research your use-case throughly and draw estimates on your execution time & memory requirements, use those to find out how much it’ll cost you to run them on AWS Lambda: https://aws.amazon.com/lambda/pricing/.
Often while designing web based systems with lots of data in hand, you’ll end up having long running compute modules in the architecture, such processes have been there since the beginning of systems engineering & just because you’re on a Serverless stack, it doesn’t mean that you can get away without them. They’re extremely useful tools with a wide variety of use cases. You might want to check for failed or pending payments on your SaaS app and initiate a reconciliation flow or you might want to backfill your data warehouse from access logs or text files periodically or you might want to move a set of files to a different location or not so commonly, you might want to invoke an external service periodically(or based on an event) and do a series of operations based on the service response.

These kind of processes are triggered mainly through external events like a user action or periodically through a CRON job. Traditionally, these kind of processes reside in persistent server environments as application processes. Since they’re in a state persistent environment itself, managing the state of such a process will be easy, you just have to be prepared for cases like the application crash, corrupt data, double or triple execution — idempotency of your operation basically.

While designing such systems in the context of Serverless architectures, it’s a different ball game all together, not only you’ll have to handle all of the perviously discussed cases, you’ll also have to take into account that the environment is transient & often you can’t keep them running forever or till all of your data is processed, there are hard limits on execution time while you’re on Serverless functions. This means that the piece of software you’re going to write will have to keep track of its state + the state of environment it is running on for it to be reliable and resilient.
For AWS Lambda, at the time of writing this article, 15 minutes is the maximum time a Lambda function can run, you can check the limits on Lambda here: https://docs.aws.amazon.com/lambda/latest/dg/long-running-lambda-functions/gettingstarted-limits.html
There are multiple ways you can design such a long running background processor with Serverless components, if you are on AWS, you could make use of Cloudformation and EC2 APIs to fire up EC2 instances on an ad-hoc basis or you can use AWS Fargate to spin up containers that’ll run till your processing is done. Downside of these approaches is that, you’re introducing additional modules into the system, even though they are created & destroyed on a need basis & virtually behaves like a Serverless component, adding more functional modules will always have its own set of challenges.
AWS Lambda Only Solution
With a bit of logic, such a system can be built purely using AWS Lambda, this function will keep on running till your data has been fully processed or till an end condition is reached. To design such a system, let’s have a look into the context object. AWS Lambda provides a context object in the lambda handler, for a Nodejs lambda function, fields and methods available on the context object can be found here: https://docs.aws.amazon.com/lambda/latest/dg/nodejs-context.html
If you look closely, there is a method getRemainingTimeInMillis(), which according to AWS:
Returns the number of milliseconds left before the execution times out.
From within a lambda function, calling context.getRemainingTimeInMillis() at any point will return the time remaining until AWS kills this lambda function. Using this pretty neat function, we can build a lambda long running process handler that will check for its remaining time and if its less than our safe value, we can async invoke the same lambda and return from the current one with a callback(null). Control flow for the same looks something like this:
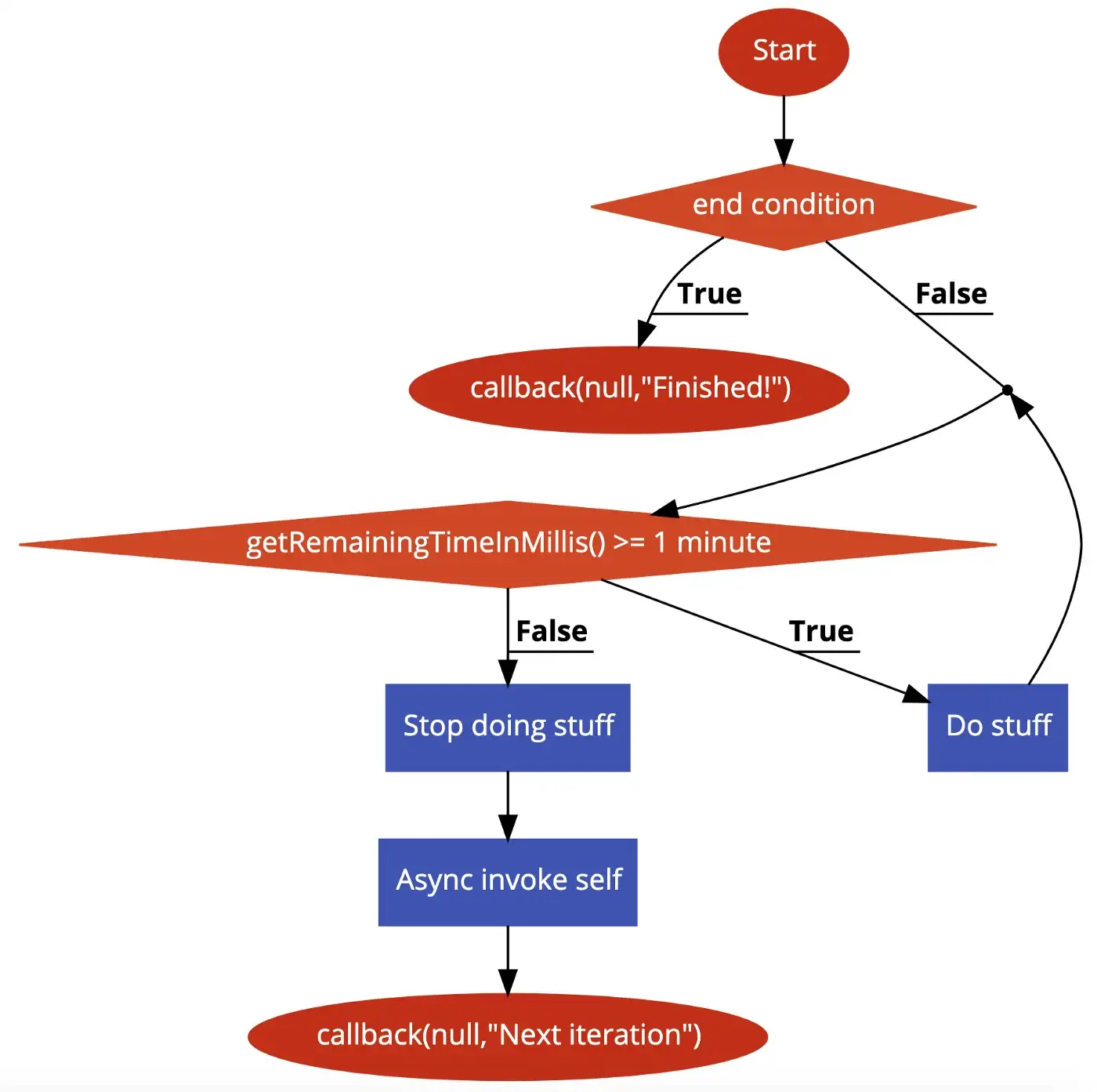
On AWS lambda, we can set the timeout of this function as 15 minutes and our safe value as 1 minute, we’ll also have to integrate this logic alongside our application logic so that we’re constantly checking if this lambda is reaching its end of life. Fundamentally, we’re making use of recursion and like all recursive functions, termination condition plays an important role here. If there is an issue with your termination condition or it does’t terminate correctly, you’ll end up with a lambda that won’t stop running, it’ll keep on invoking itself over and over till you remove it.
Below is a very minimal example of such a lambda function, note that there is no termination condition exist in this example, DO NOT use it without adding a proper termination condition, otherwise you’ll end up having a rogue lambda that is unstoppable & you’ll rack up lambda costs!
| const AWS = require('aws-sdk') | |
| const NanoTimer = require('nanotimer') | |
| const lambda = new AWS.Lambda() | |
| const SAFE_EXECUTION_MILLIS_THRESHOLD = 12 * 1000 | |
| function watchDog (context, callback) { | |
| console.log('Setting up watchdog') | |
| const timerObject = new NanoTimer() | |
| timerObject.setInterval(function () { | |
| console.log('Checking theshold', SAFE_EXECUTION_MILLIS_THRESHOLD, context.getRemainingTimeInMillis()) | |
| if (SAFE_EXECUTION_MILLIS_THRESHOLD >= context.getRemainingTimeInMillis()) { | |
| timerObject.clearInterval() | |
| console.log('My time has come!') | |
| let lambdaParams = { | |
| FunctionName: context.invokedFunctionArn, | |
| InvocationType: 'Event', | |
| Payload: JSON.stringify({ | |
| message: 'Send something logical as payload to let the lambda know that this is a continuation' | |
| }) | |
| } | |
| console.log('Invoked', lambdaParams) | |
| lambda.invoke(lambdaParams, function (error, data) { | |
| if (error) { | |
| console.log('Error while self invoking', error) | |
| return callback(error) | |
| } | |
| return callback(null, 'Bye bye!') | |
| }) | |
| } | |
| }, '', '10s') | |
| } | |
| module.exports.handler = (event, context, callback) => { | |
| // Setup our watchdog function | |
| watchDog(context, callback) | |
| if (event.source === 'aws.events') { | |
| // This invocation was made by cloudwatch! | |
| // Do the kind of stuff you need to do if this was your process entry | |
| console.log('First invocation') | |
| } else { | |
| // This was a continuation | |
| console.log('Continuation') | |
| } | |
| } |
In this example, we use Nanotimer for our watchdog function, a better alternative to setInterval(), Nanotimer is accurate & reliable enough for our use case. You can check it out here: https://www.npmjs.com/package/nanotimer.
If you look at the code, we have a SAFE_EXECUTION_MILLIS_THRESHOLD of 12000 milliseconds(12 seconds) and a watchdog function that is executed every 10 seconds. Inside the watchdog function, we’re checking if we’ve reached the safe threshold & if yes, we’re triggering the same lambda again. context.invokedFunctionArn will return the ARN of current lambda.
Do keep in mind that you’ll have to keep all timings in check, if you have a watchdog function that is executed every 5 seconds and you have a safe threshold of 2 seconds, it is never going to work correctly, your watchdog function must execute at smaller interval than your safe threshold. Also, if you have a function whose timeout is 60 seconds and your watchdog function isn’t set to execute frequent enough, you’ll end up with lambda timeouts. You might also need to store state in a persistent store such as a DB or an S3 file, consider those as well while writing such a function.
Conclusion
Hope you’ve learned a thing or two from this approach, in a future article, we’ll discuss on implementing a Serverless batch processor using AWS Lambda & AWS Fargate.